DFS&BFS
Leetcode 编程题
200. 岛屿数量
一、题目
给你一个由 '1'(陆地)和 '0'(水)组成的的二维网格,请你计算网格中岛屿的数量。
岛屿总是被水包围,并且每座岛屿只能由水平方向或竖直方向上相邻的陆地连接形成。
此外,你可以假设该网格的四条边均被水包围。
二、解析
Python 代码如下:
class Solution:
def numIslands(self, grid: List[List[str]]) -> int:
def dfs(grid, r, c):
if not (0 <= r < len(grid) and 0 <= c < len(grid[0])):
return
elif grid[r][c] == '0':
return
elif grid[r][c] != '1': ## grid[r][c] == 2
return
grid[r][c] = '2'
dfs(grid, r-1, c)
dfs(grid, r+1, c)
dfs(grid, r, c-1)
dfs(grid, r, c+1)
count = 0
for row in range(len(grid)):
for col in range(len(grid[0])):
if grid[row][col] == '1':
count += 1
dfs(grid, row, col)
return count
由于 Go 语言不支持匿名的递归函数,所以需要把递归函数定义在全局作用域。代码如下:
func numIslands(grid [][]byte) int {
count := 0
for row := 0; row < len(grid); row++ {
for col := 0; col < len(grid[0]); col++ {
if grid[row][col] == '1' {
count += 1
dfs(grid, row, col)
}
}
}
return count
}
func dfs(grid [][]byte, row, col int) {
if !(0 <= row && row < len(grid) && 0 <= col && col < len(grid[0])) {
return
} else if grid[row][col] == '0' {
return
} else if grid[row][col] != '1' { // grid[r][c] == 2
return
}
grid[row][col] = 2
dfs(grid, row-1, col)
dfs(grid, row+1, col)
dfs(grid, row, col-1)
dfs(grid, row, col+1)
return
}
695. 岛屿的最大面积
一、题目
给定一个包含了一些 0 和 1 的非空二维数组grid。
一个岛屿是由一些相邻的 1 (代表土地) 构成的组合,这里的「相邻」要求两个 1 必须在水平或者竖直方向上相邻。你可以假设 grid 的四个边缘都被 0(代表水)包围着。
找到给定的二维数组中最大的岛屿面积。(如果没有岛屿,则返回面积为 0 。)
二、解析
代码如下:
class Solution:
def maxAreaOfIsland(self, grid: List[List[int]]) -> int:
def dfs(grid, r, c):
if not (0 <= r < len(grid) and 0 <= c < len(grid[0])):
return 0
elif grid[r][c] == 0:
return 0
elif grid[r][c] != 1: ## grid[r][c] == 2
return 0
grid[r][c] = 2
return 1 + dfs(grid, r-1, c) + dfs(grid, r+1, c) + dfs(grid, r, c-1) + dfs(grid, r, c+1)
res = 0
for row in range(len(grid)):
for col in range(len(grid[0])):
if grid[row][col] == 1:
res = max(res, dfs(grid, row, col))
return res
463. 岛屿的周长
一、题目
给定一个包含 0 和 1 的二维网格地图,其中 1 表示陆地,0表示水域。
网格中的格子水平和垂直方向相连(对角线方向不相连)。整个网格被水完全包围,但其中恰好有一个岛屿(或者说,一个或多个表示陆地的格子相连组成的岛屿)。
岛屿中没有“湖”(“湖” 指水域在岛屿内部且不和岛屿周围的水相连)。格子是边长为 1 的正方形。网格为长方形,且宽度和高度均不超过 100 。计算这个岛屿的周长。
二、解析
代码如下:
class Solution:
def islandPerimeter(self, grid: List[List[int]]) -> int:
def dfs(grid, r, c):
if not (0 <= r < len(grid) and 0 <= c < len(grid[0])):
return 1
elif grid[r][c] == 0:
return 1
elif grid[r][c] != 1: ## grid[r][c] == 2
return 0
grid[r][c] = 2
return dfs(grid, r-1, c) + dfs(grid, r+1, c) + dfs(grid, r, c-1) + dfs(grid, r, c+1)
res = 0
for row in range(len(grid)):
for col in range(len(grid[0])):
if grid[row][col] == 1:
res = dfs(grid, row, col)
return res
130. 被围绕的区域
一、题目
给定一个二维的矩阵,包含 'X' 和 'O'(字母 O)。
找到所有被 'X' 围绕的区域,并将这些区域里所有的 'O' 用 'X' 填充。
示例1:
输入:board = [["X","X","X","X"],["X","O","O","X"],["X","X","O","X"],["X","O","X","X"]]
输出:[["X","X","X","X"],["X","X","X","X"],["X","X","X","X"],["X","O","X","X"]]
解释:被围绕的区间不会存在于边界上,换句话说,任何边界上的 'O' 都不会被填充为 'X'。
任何不在边界上,或不与边界上的 'O' 相连的 'O' 最终都会被填充为 'X'。如果两个元素在水平或垂直方向相邻,则称它们是“相连”的。
二、解析
参考 Leetcode官方题解
标记边界的'O'及相连的'O',没有被标记的'O'就是被包围的。
代码如下:
class Solution:
def solve(self, board: List[List[str]]) -> None:
if not board:
return
n, m = len(board), len(board[0])
def dfs(x, y):
if not 0 <= x < n or not 0 <= y < m or board[x][y] != 'O':
return
board[x][y] = "A"
dfs(x + 1, y)
dfs(x - 1, y)
dfs(x, y + 1)
dfs(x, y - 1)
for i in range(n):
dfs(i, 0)
dfs(i, m - 1)
for i in range(m - 1):
dfs(0, i)
dfs(n - 1, i)
for i in range(n):
for j in range(m):
if board[i][j] == "A":
board[i][j] = "O"
elif board[i][j] == "O":
board[i][j] = "X"
79. 单词搜索
一、题目
给定一个二维网格和一个单词,找出该单词是否存在于网格中。
单词必须按照字母顺序,通过相邻的单元格内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母不允许被重复使用。
示例:
board =
[
['A','B','C','E'],
['S','F','C','S'],
['A','D','E','E']
]
给定 word = "ABCCED", 返回 true
给定 word = "SEE", 返回 true
给定 word = "ABCB", 返回 false
二、解析
深度优先搜索+回溯。
代码如下:
class Solution:
def exist(self, board: List[List[str]], word: str) -> bool:
def dfs(board, m, n, word, x, y, index, marked):
if board[x][y] != word[index]:
return False
if index == len(word) - 1:
return True
## 先占住这个位置,搜索不成功的话,要释放掉
marked[x][y] = True
for direction in [[0, -1], [0, 1], [-1, 0], [1, 0]]:
new_x = x + direction[0]
new_y = y + direction[1]
## 如果这一次 search word 成功的话,就返回
if 0 <= new_x < m and 0 <= new_y < n and \
not marked[new_x][new_y] and \
dfs(board, m, n, word, new_x, new_y, index + 1, marked):
return True
marked[x][y] = False ## 状态重置
m = len(board)
n = len(board[0])
marked = [[False for _ in range(n)] for _ in range(m)]
for i in range(m):
for j in range(n):
## 对每一个格子都从头开始搜索
if dfs(board, m, n, word, i, j, 0, marked):
return True
return False
46. 全排列
一、题目
给定一个 没有重复 数字的序列,返回其所有可能的全排列。
示例:
输入: [1,2,3]
输出:
[
[1,2,3],
[1,3,2],
[2,1,3],
[2,3,1],
[3,1,2],
[3,2,1]
]
二、解析
深度优先搜索+回溯。
回溯法采用试错的思想,它尝试分步的去解决一个问题。在分步解决问题的过程中,当它通过尝试发现现有的分步答案不能得到有效的正确的解答的时候,它将取消上一步甚至是上几步的计算,再通过其它的可能的分步解答再次尝试寻找问题的答案。回溯法通常用最简单的递归方法来实现,在反复重复上述的步骤后可能出现两种情况: 1)找到一个可能存在的正确的答案; 2)在尝试了所有可能的分步方法后宣告该问题没有答案。
先画树形图,画图能帮助我们想清楚递归结构,想清楚如何剪枝。
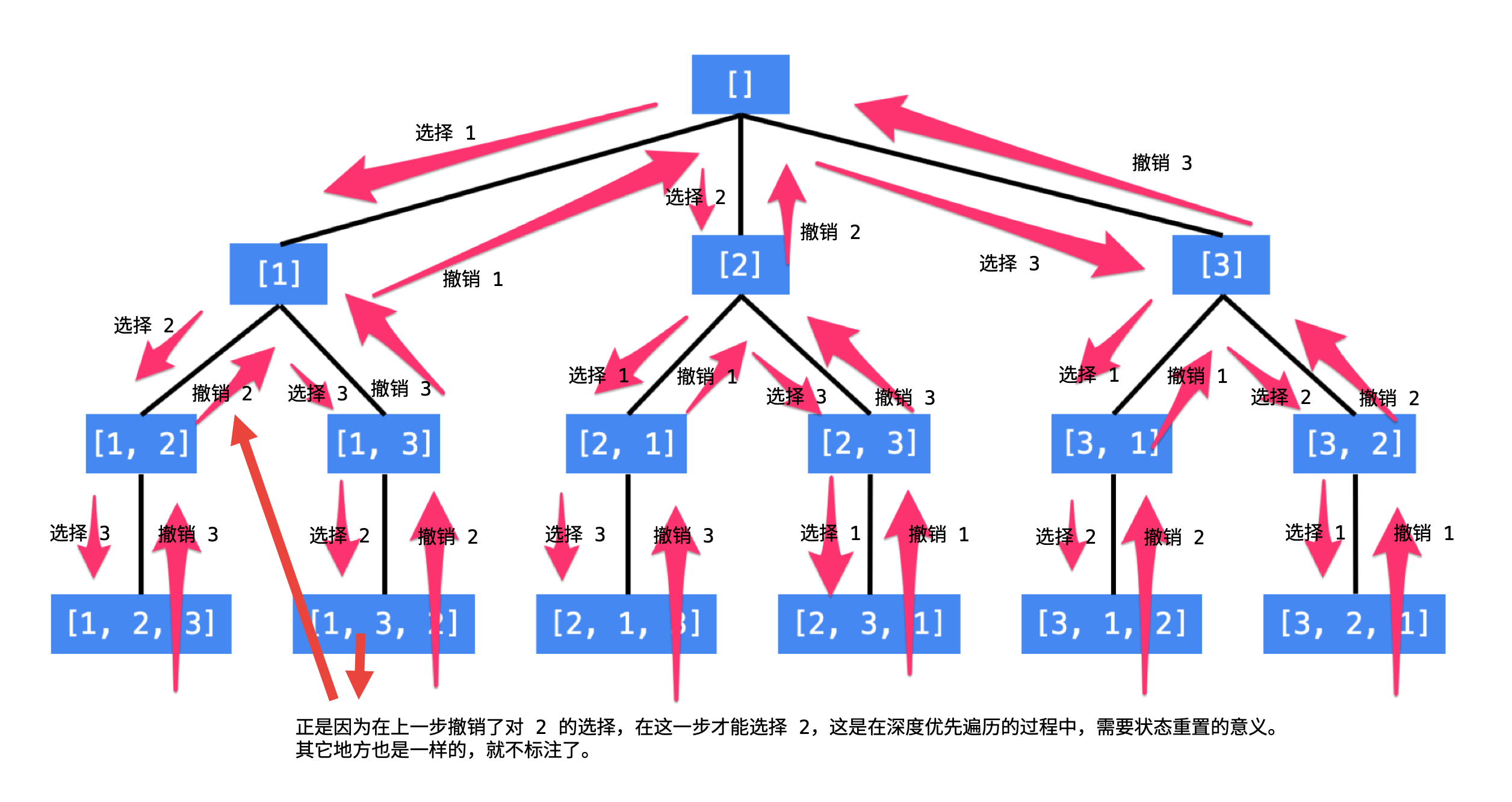
代码如下:
class Solution:
def permute(self, nums: List[int]) -> List[List[int]]:
def dfs(nums, perm, used, depth):
if depth == len(nums):
res.append(perm[:])
return
for i in range(len(nums)):
if not used[i]:
perm.append(nums[i])
used[i] = True
dfs(nums, perm, used, depth + 1)
perm.pop()
used[i] = False
if len(nums) == 0:
return []
res = []
used = [False for _ in range(len(nums))]
dfs(nums, [], used, 0)
return res
因为排列的长度是固定的,所以可以使用固定长度的list,避免append和pop操作。
Python 代码如下:
class Solution:
def permute(self, nums: List[int]) -> List[List[int]]:
def dfs(nums, perm, used, depth):
if depth == len(nums):
res.append(perm[:])
return
for i in range(len(nums)):
if not used[i]:
perm[depth] = nums[i]
used[i] = True
dfs(nums, perm, used, depth + 1)
used[i] = False
if len(nums) == 0:
return []
res = []
used = [False for _ in range(len(nums))]
perm = [0 for _ in range(len(nums))]
dfs(nums, perm, used, 0)
return res
Golang 代码如下:
func permute(nums []int) [][]int {
if len(nums) == 0 {
return nil
}
perm := make([]int, len(nums))
used := make([]bool, len(nums))
return dfs(nums, perm, used, 0)
}
func dfs(nums []int, perm []int, used []bool, depth int) [][]int {
var res [][]int
if depth == len(nums) {
res = append(res, append([]int{}, perm...))
return res
}
for i, num := range nums {
if !used[i] {
perm[depth] = num
used[i] = true
cur := dfs(nums, perm, used, depth+1)
res = append(res, cur...)
used[i] = false
}
}
return res
}
47. 全排列 II
一、题目
给定一个可包含重复数字的序列,返回所有不重复的全排列。
示例:
输入: [1,1,2]
输出:
[
[1,1,2],
[1,2,1],
[2,1,1]
]
二、解析
参考 回溯搜索 + 剪枝
画树形图。
代码如下:
class Solution:
def permuteUnique(self, nums: List[int]) -> List[List[int]]:
def dfs(nums, perm, used, depth):
if depth == len(nums):
res.append(perm[:])
return
for i in range(len(nums)):
if not used[i]:
if i > 0 and nums[i] == nums[i - 1] and not used[i - 1]:
continue
perm[depth] = nums[i]
used[i] = True
dfs(nums, perm, used, depth + 1)
used[i] = False
if len(nums) == 0:
return []
nums.sort()
res = []
used = [False for _ in range(len(nums))]
perm = [0 for _ in range(len(nums))]
dfs(nums, perm, used, 0)
return res
39. 组合总数
一、题目
给定一个无重复元素的数组candidates和一个目标数target,找出candidates中所有可以使数字和为target的组合。
candidates中的数字可以无限制重复被选取。
说明:
- 所有数字(包括
target)都是正整数。 - 解集不能包含重复的组合。
示例 1:
输入:candidates = [2,3,6,7], target = 7,
所求解集为:
[
[7],
[2,2,3]
]
二、解析
关键是如何去重。画树形图,从每一层的第2个结点开始,都不能再搜索产生同一层结点已经使用过的 candidate 里的元素。
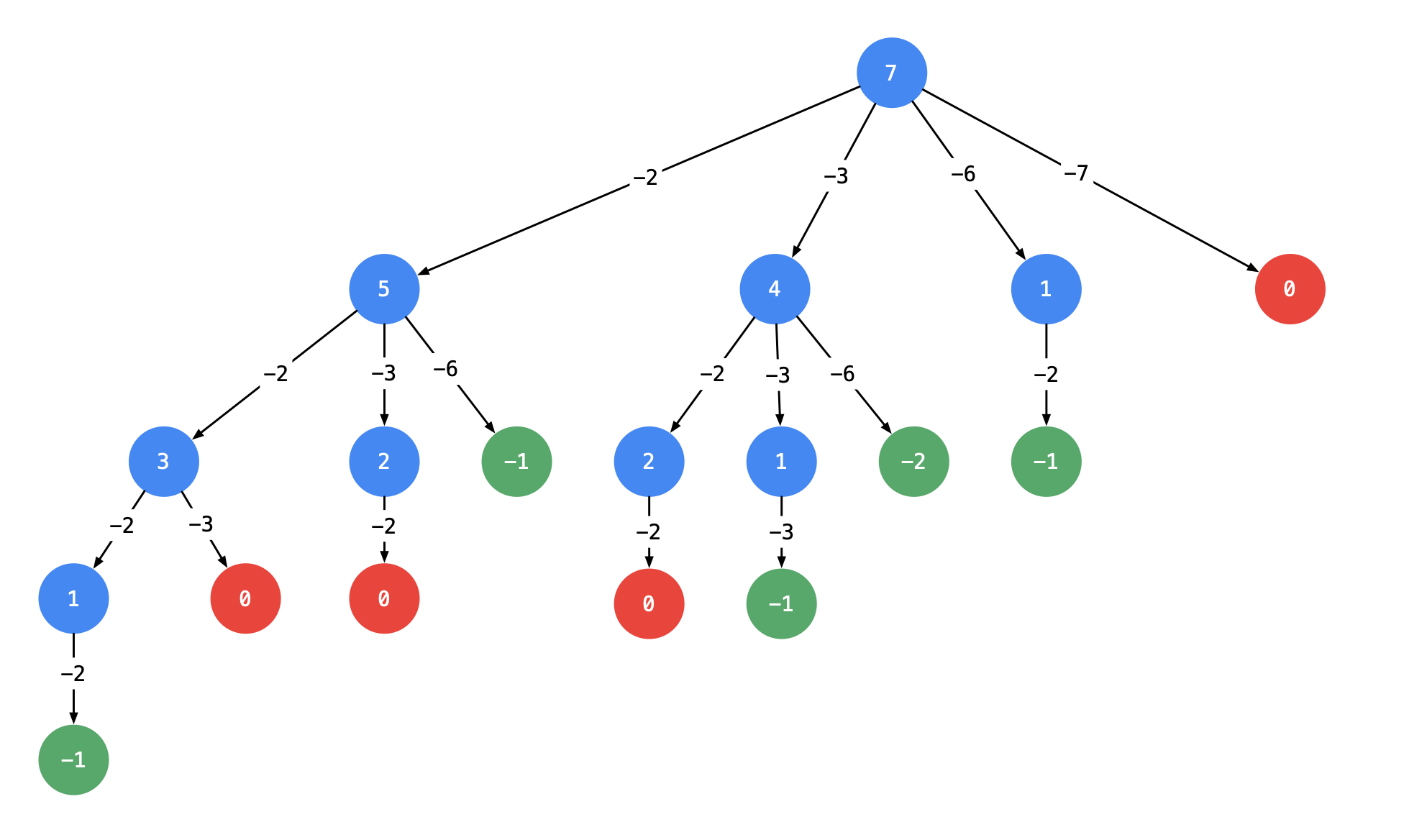
代码如下:
class Solution:
def combinationSum(self, candidates: List[int], target: int) -> List[List[int]]:
def dfs(nums, target, start, path, end):
if end < 0:
return
if end == 0:
res.append(path[:])
return
for i in range(start, size):
path.append(nums[i])
dfs(nums, target, i, path, end - nums[i])
path.pop()
size = len(candidates)
if size == 0:
return []
res = []
dfs(candidates, target, 0, [], target)
return res
对数组进行排序,使用剪枝加速:
class Solution:
def combinationSum(self, candidates: List[int], target: int) -> List[List[int]]:
def dfs(nums, target, start, path, end):
if end < 0:
return
if end == 0:
res.append(path[:])
return
for i in range(start, len(nums)):
if nums[i] > end:
break
path.append(nums[i])
dfs(nums, target, i, path, end - nums[i])
path.pop()
if len(candidates) == 0:
return []
candidates.sort()
res = []
dfs(candidates, target, 0, [], target)
return res
40. 组合总数 II
一、题目
给定一个数组candidates和一个目标数target,找出candidates中所有可以使数字和为target的组合。
candidates中的每个数字在每个组合中只能使用一次。
说明:
- 所有数字(包括
target)都是正整数。 - 解集不能包含重复的组合。
示例 1:
输入: candidates = [10,1,2,7,6,1,5], target = 8,
所求解集为:
[
[1, 7],
[1, 2, 5],
[2, 6],
[1, 1, 6]
]
二、解析
画树形图。代码如下:
class Solution:
def combinationSum2(self, candidates: List[int], target: int) -> List[List[int]]:
def dfs(nums, target, start, path, end):
if end == 0:
res.append(path[:])
return
for i in range(start, size):
if nums[i] > target:
break
if i > start and nums[i] == nums[i - 1]:
continue
path.append(nums[i])
dfs(nums, target - nums[i], i + 1, path, end - nums[i])
path.pop()
size = len(candidates)
if size == 0:
return []
res = []
candidates.sort()
dfs(candidates, target, 0, [], target)
return res
77. 组合
一、题目
给定两个整数 n 和 k,返回 1 ... n 中所有可能的 k 个数的组合。
示例:
输入: n = 4, k = 2
输出:
[
[2,4],
[3,4],
[2,3],
[1,2],
[1,3],
[1,4],
]
二、解析
1)模仿上面的代码,使用数组。
代码如下:
class Solution:
def combine(self, n: int, k: int) -> List[List[int]]:
def dfs(nums, k, start, path, depth):
if depth == k:
res.append(path[:])
return
for i in range(start, len(nums)):
## for i in range(start, len(nums) - (k - depth) + 1):
path[depth] = nums[i]
dfs(nums, k, i + 1, path, depth + 1)
nums = list(range(1, n + 1))
res = []
path = [0] * k
dfs(nums, k, 0, path, 0)
return res
2)不用数组
代码如下:
class Solution:
def combine(self, n: int, k: int) -> List[List[int]]:
def dfs(n, k, start, path, depth):
if depth == k:
res.append(path[:])
return
for i in range(start, n + 1):
path[depth] = i
dfs(n, k, i + 1, path, depth + 1)
res = []
dfs(n, k, 1, [0] * k, 0)
return res
3)剪枝
可以使用剪枝技术来提高算法效率。举例,对于n = 7, k = 4,从 5 开始搜索就已经没有意义了,这是因为:即使把 5 选上,后面的数只有 6 和 7,一共就 3 个候选数,凑不出 4 个数的组合。因此,搜索起点有上界,可以使用剪枝技术,避免不必要的遍历,加快算法。
## 1、使用数组,其中的start表示数组下标,初始为0
for i in range(start, len(nums) - (k - depth) + 1):
## 2、不用数组,其中的start表示数字,初始为1
for i in range(start, n - (k - depth) + 2):
78. 子集
一、题目
给定一组不含重复元素的整数数组 nums,返回该数组所有可能的子集(幂集)。
说明:解集不能包含重复的子集。
示例:
输入: nums = [1,2,3]
输出:
[
[3],
[1],
[2],
[1,2,3],
[1,3],
[2,3],
[1,2],
[]
]
二、解析
参考 77 题。
代码如下:
class Solution:
def subsets(self, nums: List[int]) -> List[List[int]]:
def dfs(nums, k, start, path, depth):
if depth == k:
res.append(path[:])
return
for i in range(start, len(nums)): ## 没有剪枝
## for i in range(start, len(nums) - (k - depth) + 1): ## 剪枝
path.append(nums[i])
dfs(nums, k, i + 1, path, depth + 1)
path.pop()
res = [[]]
for k in range(1, len(nums) + 1):
dfs(nums, k, 0, [], 0)
return res
90. 子集 II
一、题目
给定一个可能包含重复元素的整数数组 nums,返回该数组所有可能的子集(幂集)。
说明:解集不能包含重复的子集。
示例:
输入: [1,2,2]
输出:
[
[2],
[1],
[1,2,2],
[2,2],
[1,2],
[]
]
二、解析
参考 78 题,剪枝技巧同 47 题、40 题。
代码如下:
class Solution:
def subsetsWithDup(self, nums: List[int]) -> List[List[int]]:
def dfs(nums, k, start, path, depth):
if depth == k:
res.append(path[:])
return
for i in range(start, len(nums)): ## 没有剪枝
## for i in range(start, len(nums) - (k - depth) + 1): ## 剪枝
if i > start and nums[i] == nums[i - 1]:
continue
path.append(nums[i])
dfs(nums, k, i + 1, path, depth + 1)
path.pop()
res = [[]]
nums.sort()
for k in range(1, len(nums) + 1):
dfs(nums, k, 0, [], 0)
return res
60. 第k个排列
一、题目
给出集合 [1,2,3,…,n],其所有元素共有 n! 种排列。
按大小顺序列出所有排列情况,并一一标记,当 n = 3 时, 所有排列如下:
- "123"
- "132"
- "213"
- "231"
- "312"
- "321"
给定 n 和 k,返回第 k 个排列。
说明:
- 给定 n 的范围是 [1, 9]。
- 给定 k 的范围是 [1, n!]。
二、解析
1)参考 46 题。
代码如下:
class Solution:
def getPermutation(self, n: int, k: int) -> str:
def dfs(nums, k, path, used, depth):
if depth == len(nums):
res[0] += 1
if res[0] == k:
res[1] = "".join(str(d) for d in path)
return
for i in range(len(nums)):
if not used[i]:
path.append(nums[i])
used[i] = True
dfs(nums, k, path, used, depth + 1)
path.pop()
used[i] = False
if res[0] == k: ## 得到结果即返回
break
nums = list(range(1, n + 1))
res = [0, ""]
used = [False for _ in range(n)]
dfs(nums, k, [], used, 0)
return res[1]
2)剪枝
画树形图,所求排列一定在叶子结点处得到,每个分支下的叶结点个数可求,所以不必求出所有的全排列。
代码如下:
class Solution:
def getPermutation(self, n: int, k: int) -> str:
def dfs(n, k, start, path, depth):
if depth == n:
return
cnt = factorial[n - 1 - depth]
for i in range(1, n + 1):
if used[i]:
continue
if cnt < k:
k -= cnt
continue
path.append(i)
used[i] = True
dfs(n, k, start, path, depth + 1)
## 注意:这里要加 return,后面的数没有必要遍历去尝试了
return
if n == 0:
return ""
used = [False for _ in range(n + 1)]
path = []
factorial = [1 for _ in range(n + 1)]
for i in range(2, n + 1):
factorial[i] = factorial[i - 1] * i
dfs(n, k, 0, path, 0)
return ''.join([str(num) for num in path])
93. 复原IP地址
一、题目
有效的 IP 地址 正好由四个整数(每个整数位于 0 到 255 之间组成,且不能含有前导 0),整数之间用 '.' 分隔。
- 如:"0.1.2.201" 和 "192.168.1.1" 是 有效的 IP 地址,但是 "0.011.255.245"、"192.168.1.312" 和 "192.168@1.1" 是 无效的 IP 地址。
给定一个只包含数字的字符串 s ,用以表示一个 IP 地址,返回所有可能的有效 IP 地址,这些地址可以通过在 s 中插入 '.' 来形成。你 不能 重新排序或删除 s 中的任何数字。你可以按 任何 顺序返回答案。
示例 1:
输入:s = "25525511135"
输出:["255.255.11.135","255.255.111.35"]
示例 2:
输入:s = "0000"
输出:["0.0.0.0"]
示例 3:
输入:s = "101023"
输出:["1.0.10.23","1.0.102.3","10.1.0.23","10.10.2.3","101.0.2.3"]
二、解析
Python 代码如下:
class Solution:
def restoreIpAddresses(self, s: str) -> List[str]:
def dfs(s, seg_start, segments, seg_id):
## 如果找到了 4 段 IP 地址并且遍历完了字符串,那么就是一种答案
if seg_start == len(s) and seg_id == 4:
if seg_start == len(s):
ip_addr = ".".join(str(seg) for seg in segments)
res.append(ip_addr)
return
## 如果还没有找到 4 段 IP 地址就已经遍历完了字符串,那么提前回溯
if seg_start == len(s) or seg_id == 4:
return
## 由于不能有前导零,如果当前数字为 0,那么这一段 IP 地址只能为 0
if s[seg_start] == "0":
segments[seg_id] = 0
dfs(s, seg_start + 1, segments, seg_id + 1)
## 一般情况,枚举每一种可能性并递归
addr = 0
for idx in range(seg_start, len(s)):
addr = addr * 10 + (ord(s[idx]) - ord("0"))
if 0 < addr <= 0xFF:
segments[seg_id] = addr
dfs(s, idx + 1, segments, seg_id + 1)
else:
break
SEG_COUNT = 4
res = []
dfs(s, 0, [0,0,0,0], 0)
return res
Golang 无法在函数内声明一个带递归的匿名函数,只能在全局作用域声明。
代码如下:
func restoreIpAddresses(s string) []string {
return restore(s, []int{0, 0, 0, 0}, 0, 0)
}
func restore(s string, ip []int, start int, no int) []string {
if start == len(s) && no == 4 {
ipStr := fmt.Sprintf("%d.%d.%d.%d", ip[0], ip[1], ip[2], ip[3])
return []string{ipStr}
}
if start == len(s) || no == 4 {
return nil
}
var total []string
if s[start] == '0' {
ip[no] = 0
res := restore(s, ip, start+1, no+1)
total = append(total, res...)
return total
}
seg := 0
for i := start; i < len(s); i++ {
seg = seg*10 + int(rune(s[i])-'0')
if 0 < seg && seg <= 255 {
ip[no] = seg
res := restore(s, ip, i+1, no+1)
total = append(total, res...)
} else {
break
}
}
return total
}
17. 电话号码的字母组合
一、题目
给定一个仅包含数字 2-9 的字符串,返回所有它能表示的字母组合。
给出数字到字母的映射如下(与电话按键相同)。注意 1 不对应任何字母。
示例:
输入:"23"
输出:["ad", "ae", "af", "bd", "be", "bf", "cd", "ce", "cf"].
二、解析
经典回溯。
代码如下:
class Solution:
def letterCombinations(self, digits: str) -> List[str]:
def dfs(digits, phone_map, index, combination):
if index == len(digits):
res.append("".join(combination))
return
digit = digits[index]
for letter in phone_map[digit]:
combination.append(letter)
dfs(digits, phone_map, index + 1, combination)
combination.pop()
if not digits:
return []
phone_map = {
"2": "abc",
"3": "def",
"4": "ghi",
"5": "jkl",
"6": "mno",
"7": "pqrs",
"8": "tuv",
"9": "wxyz",
}
res = []
dfs(digits, phone_map, 0, [])
return res
22. 括号生成
一、题目
数字 n 代表生成括号的对数,请你设计一个函数,用于能够生成所有可能的并且 有效的 括号组合。
示例 1:
输入:n = 3
输出:["((()))","(()())","(())()","()(())","()()()"]
示例 2:
输入:n = 1
输出:["()"]
二、解析
代码如下:
class Solution:
def generateParenthesis(self, n: int) -> List[str]:
def dfs(cur_str, left, right):
if left == 0 and right == 0:
res.append(cur_str)
return
if left > 0:
dfs(cur_str + '(', left - 1, right)
if right > left:
dfs(cur_str + ')', left, right - 1)
res = []
dfs("", n, n)
return res
或者
class Solution:
def generateParenthesis(self, n: int) -> List[str]:
def dfs(cur_str, left, right):
res = []
if left == 0 and right == 0:
res.append(cur_str)
return res
if left > 0:
left_res = dfs(cur_str + '(', left - 1, right)
res.extend(left_res)
if right > left:
right_res = dfs(cur_str + ')', left, right - 1)
res.extend(right_res)
return res
return dfs("", n, n)
其他
奇怪的电梯
一、题目
大楼的每一层楼都可以停电梯,而且第i层楼(1≤i≤N)(1≤i≤N)上有一个数字Ki(0≤=Ki≤=N)。电梯只有四个按钮:开,关,上,下。上下的层数等于当前楼层上的那个数字。当然,如果不能满足要求,相应的按钮就会失灵。例如:3 3 1 2 5代表了Ki(K1=3,K2=3,……),从一楼开始。在一楼,按“上”可以到44楼,按“下”是不起作用的,因为没有−2楼。那么,从A楼到B楼至少要按几次按钮呢?
输入:共有二行,第一行为三个用空格隔开的正整数,表示N,A,B(1≤N≤200,1≤A,B≤N),第二行为N个用空格隔开的正整数,表示Ki。
输出:一行,即最少按键次数,若无法到达,则输出−1。
示例:
输入:
5 1 5
3 3 1 2 5
输出:
3
二、解析
广度优先搜索。