介绍
图的表示
算法导论-第三版
图有多种表示方法,比较常用的表示法有邻接链表和邻接矩阵。
根据边的方向,图可以分为无向图和有向图;根据边的权重,图可以分为带权图和不带权图。
对于图,其邻接链表表示由一个包含条链表的数组所构成,每个结点有一条链表。对于每个结点,邻接链表包含所有与结点之间有边相连的结点,即包含图中所有与邻接的结点(也可以说,该链表里包含指向这些结点的指针)。由于邻接链表代表的是图的边,在伪代码里,我们将数组看做是图的一个属性,就如我们将边集合看做是图的属性一样。因此,在伪代码里,我们将看到这样的表示。
对于邻接链表稍加修改,即可以用来表示权重图(带权图)。权重图是图中的每条边都带有一个相关的权重的图。该权重值通常有一个的权重函数给出。例如,设为一个权重图,其权重函数为,我们可以直接将边的权重值存放在结点的邻接链表里。
对于邻接矩阵表示来说,我们通常会将图G 中的结点编为,这种编号是任意的。在进行此种编号之后,图的邻接矩阵表示由一个的矩阵予以表示,该矩阵满足下述条件:
与邻接链表表示法一样,邻接矩阵也可以用来是表示权重图。例如,如果为一个权重图,其权重函数为,则我们直接将边的权重存放在第行第列记录上。对于不存在的边,则在相应的行列记录上存放NIL(空值)。不过,对于许多问题来说,用0或者∞来表示一条不存在的边可能更为便捷。
下图给出一个无向图及其两种表示(来自算法导论):
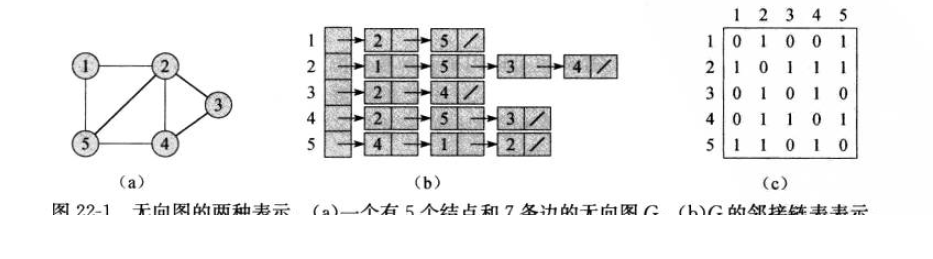
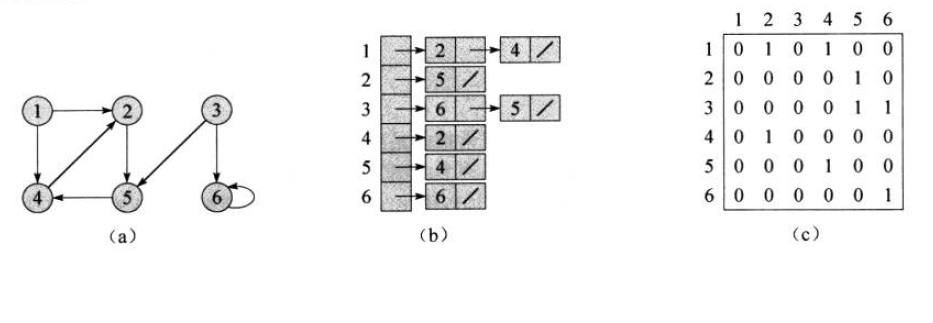
下图给出一个有向图及其两种表示(来自算法导论):
不管是无向图还是有向图,邻接链表表示法的存储空间需求均为。不管一个图有多少条边,邻接矩阵的空间需求均为。
虽然邻接链表表示法和邻接矩阵表示法在渐近意义下至少是一样空间有效的,但邻接矩阵表示法更为简单,因此在图规模比较小时,我们可能更倾向于使用邻接矩阵表示法。而且,对于无向图来说,邻接矩阵还有一个优势:每个记录只需要一位的空间。
在 Python 中,邻接矩阵可以用二维列表来表示,邻接链表可以用字典 map 和列表 list 来表示,其中列表也可以换成集合 set。
对于上面的无向图,邻接矩阵和邻接链表的表示如下所示:
## 邻接矩阵
graph = [
[0, 1, 0, 0, 1],
[1, 0, 1, 1, 1],
[0, 1, 0, 1, 0],
[0, 1, 1, 0, 1],
[1, 1, 0, 1, 0],
]
## 邻接链表
graph = {
1: [2, 5],
2: [1, 3, 4, 5],
3: [2, 4],
4: [2, 3, 5],
5: [1, 2, 4],
}
对于上面的有向图,邻接矩阵和邻接链表的表示如下所示:
## 邻接矩阵
graph = [
[0, 1, 0, 1, 0, 0],
[0, 0, 0, 0, 1, 0],
[0, 0, 0, 0, 1, 1],
[0, 1, 0, 0, 0, 0],
[0, 0, 0, 1, 0, 0],
[0, 0, 0, 0, 0, 1],
]
## 邻接链表
graph = {
1: [2, 4],
2: [5],
3: [5, 6],
4: [2],
5: [4],
6: [6],
}
图的遍历
图的遍历,指的是从图中的任一顶点出发,对图中的所有顶点访问一次且只访问一次。图的遍历操作和树的遍历操作功能相似。图的遍历是图的一种基本操作,图的许多其它操作都是建立在遍历操作的基础之上。
由于图结构本身的复杂性,所以图的遍历操作也较复杂,主要表现在以下四个方面:
- 在图结构中,没有一个自然的首结点,任意一个顶点都可作为第一个被访问的结点,所以在遍历前需要指定一个开始结点。
- 在非连通图中,从一个顶点出发,只能够访问它所在的连通分量上的所有顶点,因此,还需考虑如何选取下一个出发点以访问图中其余的连通分量。
- 在图结构中,如果有回路存在,那么一个顶点被访问之后,有可能沿回路又回到该顶点。
- 在图结构中,一个顶点可以和其它多个顶点相连,当这样的顶点访问过后,存在如何选取下一个要访问的顶点的问题。
图的遍历方法目前有两种算法:广度(宽度)优先搜索和深度优先搜索。在广度优先搜索算法中,我们把源结点的数量限制为一个,而深度优先搜索则可以有多个源结点,因为广度优先搜索通常用来寻找从特定源结点出发的最短路径距离(及其相关的前驱子图),而深度优先搜索则常常作为另一个算法里的一个子程序。
广度优先搜索
给定图和一个可以识别的源结点,广度优先搜索对图中的边进行系统性的探索来发现可以从源结点到达的所有结点。该算法能够计算从源结点到每个可到达的结点的距离(最少的边数),同时生成一棵“广度优先搜索树”。该树以源结点为根结点,包含所有可从到达的结点。对于每个可以从源结点到达的结点,在广度优先搜索树里从结点到结点的简单路径所对应的就是图中从结点到结点的“最短路径”,即包含最少边数的路径。该算法既可以用于有向图,也可以用于无向图。
广度优先搜索之所以如此得名是因为该算法始终是将已发现结点和未发现结点之间的边界,沿其广度方向向外扩展。也就是说,广度优先搜索需要在发现距离源结点为的所有结点之后,才会发现距离源结点为的其他结点。广度优先搜索的时间复杂度为。
对于一个用邻接链表表示的图,广度优先搜索的代码如下所示:
def BFS(graph, start):
res = []
visited = {node: False for node in graph.keys()}
visited[start] = True
distances = {start: 0}
predecessors = {start: None}
queue = [start]
while len(queue) > 0:
node = queue.pop(0) ## 最好使用双向队列collections.deque
res.append(node)
for adj_node in graph[node]:
if not visited[adj_node]:
visited[adj_node] = True
distances[adj_node] = distances[node] + 1
predecessors[adj_node] = node
queue.append(adj_node)
return res, distances, predecessors
if __name__ == "__main__":
graph = {
1: [2, 5],
2: [1, 3, 4, 5],
3: [2, 4],
4: [2, 3, 5],
5: [1, 2, 4],
}
res, distances, predecessors = BFS(graph, 1)
print(res) ## [1, 2, 5, 3, 4]
print(distances) ## {1: 0, 2: 1, 5: 1, 3: 2, 4: 2}
print(predecessors) ## {1: None, 2: 1, 5: 1, 3: 2, 4: 2}
深度优先搜索
深度优先搜索所使用的策略就像其名字所隐含的:只要可能,就在图中尽量“深入”。深度优先搜索总是对最近才发现的结点的出发边进行探索,直到该结点的所有出发边都被发现为止。一旦结点的所有出发边都被发现,搜索则“回溯”到的前驱结点(是经过该结点才被发现的),来搜索该前驱结点的出发边。该过程一直持续到从源结点可以到达的所有结点都被发现为止。如果还存在尚未发现的结点,则深度优先搜索将从这些未被发现的结点中任选一个作为新的源结点,并重复同样的搜索过程。
深度优先搜索的时间复杂度为。
对于一个用邻接链表表示的图(无向图和有向图均可),深度优先搜索的代码如下所示:
def DFS(graph, start, use_loop=True):
"""只适用于连通图,需要指定源结点"""
res = []
visited = {node: False for node in graph.keys()}
if use_loop:
DFS_loop(graph, start, visited, res)
else:
DFS_recursive(graph, start, visited, res)
return res
def DFS2(graph, use_loop=True):
"""适用于连通图和非连通图,不需要指定源结点"""
res = []
visited = {node: False for node in graph.keys()}
if use_loop:
for node in graph.keys(): ## 最终的遍历结果依赖于结点的访问顺序
if not visited[node]:
DFS_loop(graph, node, visited, res)
else:
for node in graph.keys(): ## 最终的遍历结果依赖于结点的访问顺序
if not visited[node]:
DFS_recursive(graph, node, visited, res)
return res
def DFS_loop(graph, start, visited, res):
"""深度优先搜索,循环方法,使用栈。
对于只适用于连通图的DFS,可以不使用visited和res两个参数,
而是在此函数内部定义二者,并在最后返回遍历结果res。
"""
visited[start] = True
stack = [start]
while len(stack) > 0:
node = stack.pop()
res.append(node)
for adj_node in reversed(graph[node]): ## 最终的遍历结果依赖于结点的访问顺序
if not visited[adj_node]:
visited[adj_node] = True
stack.append(adj_node)
def DFS_recursive(graph, start, visited, res):
"""深度优先搜索,递归方法"""
visited[start] = True
res.append(start)
for node in graph[start]: ## 最终的遍历结果依赖于结点的访问顺序
if not visited[node]:
DFS_recursive(graph, node, visited, res)
if __name__ == "__main__":
graph = {
1: [2, 5],
2: [1, 3, 4, 5],
3: [2, 4],
4: [2, 3, 5],
5: [1, 2, 4],
}
res = DFS(graph, 1, True)
print(res) ## [1, 2, 3, 4, 5]
res = DFS(graph, 1, False)
print(res) ## [1, 2, 3, 4, 5]
res = DFS2(graph, True)
print(res) ## [1, 2, 3, 4, 5]
res = DFS2(graph, False)
print(res) ## [1, 2, 3, 4, 5]
拓扑排序
对于一个有向无环图来说,其拓扑排序是中所有结点的一种线性排序,该次序满足以下条件:如果图包含边,则结点在拓扑排序中处于结点的前面(如果图包含环路,则不可能排出一个线性次序)。许多实际应用都需要使用有向无环图来指明事件的优先次序。
对于一个用邻接链表表示的有向无环图,可以使用深度优先搜索对其进行拓扑排序,如下所示:
def DFS_recursive(graph, start, visited, res):
"""深度优先搜索,递归方法"""
visited[start] = True
for node in graph[start]:
if not visited[node]:
DFS_recursive(graph, node, visited, res)
res.insert(0, start)
def topological_sort(graph):
res = []
visited = {node: False for node in graph.keys()}
for node in range(len(graph)):
if not visited[node]:
DFS_recursive(graph, node, visited, res)
return res
if __name__ == "__main__":
clothes = {
0: "underwear",
1: "pants",
2: "belt",
3: "suit",
4: "shoe",
5: "socks",
6: "shirt",
7: "tie",
8: "watch",
}
graph = {
0: [1, 4],
1: [2, 4],
2: [3],
3: [],
4: [],
5: [4],
6: [2, 7],
7: [3],
8: [],
}
res = topological_sort(graph)
for ele in res:
print(str(ele) + "-" + clothes[ele], end=" ")
## 8-watch 6-shirt 7-tie 5-socks 0-underwear 1-pants 4-shoe 2-belt 3-suit
经过拓扑排序后的结点次序,与结点的完成时间恰好相反,所以在DFS_recursive的最后一行保存结果。拓扑排序的时间复杂度为,因为深度优先搜索的运行时间为。
在有向无环图上执行拓扑排序还有一种方法,就是重复寻找入度为0的结点,输入该结点,将该结点及从其发出的边从图中删除。
最小生成树
对于一个带权重的连通无向图和权重函数,该权重函数将每条边映射到实数值的权重上。最小生成树(Minimum Spanning Tree,MST)问题是指,找到一个无环子集,能够将所有的结点连接起来,又具有最小的权重。
解决最小生成树问题有两种算法:Kruskal算法和Prim算法。这两种算法都是贪心算法。贪心算法通常在每一步有多个可能的选择,并推荐选择在当前看来最好的选择。这种策略一般并不能保证找到一个全局最优的解决方案。但是,对于最小生成树问题来说,可以证明,Kruskal算法和Prim算法使用的贪心策略确实能够找到一棵权重最小的生成树。
Kruskal
对于一个带权重的连通无向图,Kruskal算法把图中的每一个结点看作一棵树,所以图中的所有结点可以组成一个森林。该算法按照边的权重大小依次进行考虑,如果一条边可以将两棵不同的树连接起来,它就被加入到森林中,从而完成对两棵树的合并。
在Kruskal算法的实现中,使用了一种叫做并查集的数据结构,其作用是用来维护几个不相交的元素集合。在该算法中,每个集合代表当前森林中的一棵树。
Kruskal算法的运行时间依赖于不相交集合数据结构的实现方式。如果使用不相交集合森林(并查集)实现,Kruskal算法的总运行时间为。
对于一个用邻接链表表示的带权重的连通无向图,Kruskal算法的实现如下所示:
def mst_kruskal(graph, weights):
edges = []
for edge, weight in weights.items():
if edge[0] < edge[1]:
edges.append((edge, weight))
edges.sort(key=lambda x: x[1])
parents = {node: node for node in graph}
def find_parent(node):
if node != parents[node]:
parents[node] = find_parent(parents[node])
return parents[node]
minimum_cost = 0
minimum_spanning_tree = []
for edge in edges:
parent_from_node = find_parent(edge[0][0])
parent_to_node = find_parent(edge[0][1])
if parent_from_node != parent_to_node:
minimum_cost += edge[1]
minimum_spanning_tree.append(edge)
parents[parent_from_node] = parent_to_node
return minimum_spanning_tree, minimum_cost
if __name__ == "__main__":
## 算法导论图23-4
graph = {
"a": ["b", "h"],
"b": ["a", "c", "h"],
"c": ["b", "d", "f", "i"],
"d": ["c", "e", "f"],
"e": ["d", "f"],
"f": ["c", "d", "e", "g"],
"g": ["f", "h", "i"],
"h": ["a", "b", "g", "i"],
"i": ["c", "g", "h"],
}
weights = {
("a", "b"): 4, ("a", "h"): 8,
("b", "a"): 4, ("b", "c"): 8, ("b", "h"): 11,
("c", "b"): 8, ("c", "d"): 7, ("c", "f"): 4, ("c", "i"): 2,
("d", "c"): 7, ("d", "e"): 9, ("d", "f"): 14,
("e", "d"): 9, ("e", "f"): 10,
("f", "c"): 4, ("f", "d"): 14, ("f", "e"): 10, ("f", "g"): 2,
("g", "f"): 2, ("g", "h"): 1, ("g", "i"): 6,
("h", "a"): 8, ("h", "b"): 11, ("h", "g"): 1, ("h", "i"): 7,
("i", "c"): 2, ("i", "g"): 6, ("i", "h"): 7,
}
minimum_spanning_tree, minimum_cost = mst_kruskal(graph, weights)
print(minimum_spanning_tree)
print(minimum_cost)
## [(('g', 'h'), 1), (('c', 'i'), 2), (('f', 'g'), 2), (('a', 'b'), 4), (('c', 'f'), 4), (('c', 'd'), 7), (('a', 'h'), 8), (('d', 'e'), 9)]
## 37
Prim
对于一个带权重的连通无向图,Prim算法从图中任意一个结点开始建立最小生成树,这棵树一直长大到覆盖中的所有结点为止。与Kruskal算法不同,该算法始终保持只有一棵树,每一步选择与当前的树相邻的权重最小的一条边(也就是选择与当前的树最近的一个结点),加入到这棵树中。当算法终止时,所有已选择的边形成一棵最小生成树。本策略也属于贪心策略,因为每一步所加入的边都必须是使树的总权重增加量最小的边。
在Prim算法的实现中,需要使用最小优先队列来快速选择一条新的边,以便加入到已选择的边构成的树中。所以,在算法的执行过程中,对于不在当前的树中的每一个结点,需要记录其和树中结点的所有边中最小边的权重。
Prim算法的运行时间取决于最小优先队列的实现方式。如果最小优先队列使用二叉最小优先队列(最小堆),该算法的时间复杂度为。从渐进意义上来说,它与Kruskal算法的运行时间相同。如果使用斐波那契堆来实现最小优先队列,则Prim算法的运行时间将改进到。
对于一个用邻接链表表示的带权重的连通无向图,Prim算法的实现如下所示:
class MinHeap:
def __init__(self, nodes, keys):
"""
:param nodes: 保存结点元素
:param keys: 保存结点的关键值
item_pos: 保存结点元素在堆中的下标
"""
self.heap = nodes
self.size = len(nodes)
self.keys = keys
self.item_pos = {item: i for i, item in enumerate(self.heap)}
self._heapify()
def __len__(self):
return self.size
def _siftup(self, pos):
"""当前元素上筛"""
old_item = self.heap[pos]
while pos > 0:
parent_pos = (pos - 1) >> 1
parent_item = self.heap[parent_pos]
if self.keys[old_item] < self.keys[parent_item]:
self.heap[pos] = parent_item
self.item_pos[parent_item] = pos
pos = parent_pos
else:
break
self.heap[pos] = old_item
self.item_pos[old_item] = pos
def _siftdown(self, pos):
"""当前元素下筛"""
old_item = self.heap[pos]
child_pos = 2 * pos + 1 ## left child position
while child_pos < self.size:
child_item = self.heap[child_pos]
right_child_pos = child_pos + 1
right_child_item = self.heap[right_child_pos]
if right_child_pos < self.size and \
self.keys[child_item] > self.keys[right_child_item]:
child_pos = right_child_pos
child_item = self.heap[child_pos]
if self.keys[old_item] > self.keys[child_item]:
self.heap[pos] = child_item
self.item_pos[child_item] = pos
pos = child_pos
child_pos = 2 * pos + 1 ## 更新循环判断条件
else:
break
self.heap[pos] = old_item
self.item_pos[old_item] = pos
def _heapify(self):
for i in reversed(range(self.size // 2)):
self._siftdown(i)
def extract_min(self):
old_item = self.heap[0]
self.heap[0] = self.heap[self.size - 1]
self.item_pos[self.heap[0]] = 0
self.heap[self.size - 1] = old_item
self.item_pos[old_item] = self.size - 1
self.size -= 1
self._siftdown(0)
return old_item
def decrease_key(self, item):
pos = self.item_pos[item]
self._siftup(pos)
def contains(self, item):
return self.item_pos[item] < self.size
def mst_prim(graph, weights, start):
keys = {} ## 保存每个结点的关键值(与树的最小距离)
predecessors = {} ## 保存每个结点在最小生成树中的父结点
for node in graph.keys():
keys[node] = float("INF")
predecessors[node] = None
keys[start] = 0
priority_queue = MinHeap(list(graph.keys()), keys)
minimum_spanning_tree = []
minimum_cost = 0
while len(priority_queue) > 0:
node = priority_queue.extract_min()
minimum_spanning_tree.append((node, predecessors[node]))
edge = (node, predecessors[node])
if edge in weights:
minimum_cost += weights[edge]
for adj_node in graph[node]:
if priority_queue.contains(adj_node) and weights[(node, adj_node)] < keys[adj_node]:
predecessors[adj_node] = node
keys[adj_node] = weights[(node, adj_node)]
priority_queue.decrease_key(adj_node)
return minimum_spanning_tree, minimum_cost
if __name__ == "__main__":
## 算法导论图23-5
graph = {
"a": ["b", "h"],
"b": ["a", "c", "h"],
"c": ["b", "d", "f", "i"],
"d": ["c", "e", "f"],
"e": ["d", "f"],
"f": ["c", "d", "e", "g"],
"g": ["f", "h", "i"],
"h": ["a", "b", "g", "i"],
"i": ["c", "g", "h"],
}
weights = {
("a", "b"): 4, ("a", "h"): 8,
("b", "a"): 4, ("b", "c"): 8, ("b", "h"): 11,
("c", "b"): 8, ("c", "d"): 7, ("c", "f"): 4, ("c", "i"): 2,
("d", "c"): 7, ("d", "e"): 9, ("d", "f"): 14,
("e", "d"): 9, ("e", "f"): 10,
("f", "c"): 4, ("f", "d"): 14, ("f", "e"): 10, ("f", "g"): 2,
("g", "f"): 2, ("g", "h"): 1, ("g", "i"): 6,
("h", "a"): 8, ("h", "b"): 11, ("h", "g"): 1, ("h", "i"): 7,
("i", "c"): 2, ("i", "g"): 6, ("i", "h"): 7,
}
minimum_spanning_tree, minimum_cost = mst_prim(graph, weights, "a")
print(minimum_spanning_tree)
print(minimum_cost)
## [('a', None), ('b', 'a'), ('h', 'a'), ('g', 'h'), ('f', 'g'), ('c', 'f'), ('i', 'c'), ('d', 'c'), ('e', 'd')]
## 37
最短路径
给定一个带权重的有向图和权重函数,该权重函数将每条边映射到实数值的权重上。最短路径问题包括单源最短路径和所有结点对的最短路径问题。
- 单源最短路径问题是指,给定源结点,找到该结点到每个结点的最短路径。
- 所有结点对的最短路径问题是指,对于所有的结点对,找到从结点到结点的最短路径。
最短路径的一个重要性质是:两个结点之间的一条最短路径包含着其他的最短路径。简单来说,一条最短路径的所有子路径都是最短路径。
某些单源最短路径问题可能包含权重为负值的边。但只要图中不包含从源结点可以到达的权重为负值的环路,则对于所有的结点,最短路径权重都有精确定义,是可以计算的,即使其取值是负数。
单源最短路径的常用算法有Bellman-Ford算法和DijkiStra算法。DijkiStra算法假设输入图的所有的边权重为非负值。如果图中有权重为负值的边,则无法应用DijkiStra算法。而Bellman-Ford算法允许图中含有负权重的边,但不能有可以从源结点到达的权重为负值的环路。在通常情况下,如果存在一条权重为负值的环路,Bellman-Ford算法可以侦测并报告其存在。
所有结点对的最短路径问题可以通过运行次单源最短路径算法来解决,每一次使用一个不同的结点作为源结点。如果图中所有的边的权重为非负值,可以使用Dijkistra算法。如果图中有权重为负值的边,那么只能使用效率更低的Bellman-Ford算法。
但是,所有结点对的最短路径问题有更好的算法,Floyd-Warshall算法和Johnson算法。
Bellman-Ford
Bellman-Ford 算法解决的是一般情况下的单源最短路径问题,允许图中边的权重为负值。该算法比较简单,并且还能够侦测是否存在从源结点可以到达的权重为负值的环路。
Bellman-Ford算法通过对边进行松弛操作来渐进地降低从源结点到每个结点的最短路径的估计距离,直到得到最终的最短路径。当且仅当输入图不包含可以从源结点到达的权重为负值的环路,该算法返回TRUE值,反之返回FALSE值。
Bellman-Ford算法的运行时间为。
对于一个用邻接链表表示的带权重的有向图,Bellman-Ford算法的实现如下所示:
def intialize_single_source(graph, start):
distances = {} ## 结点的关键值
predecessors = {} ## 前驱
for node in graph.keys():
distances[node] = float("inf")
predecessors[node] = None
distances[start] = 0
return distances, predecessors
def relax(u, v, w, distances, predecessors):
if distances[v] > distances[u] + w[(u, v)]:
distances[v] = distances[u] + w[(u, v)]
predecessors[v] = u
def bellman_ford(graph, weights, start):
distances, predecessors = intialize_single_source(graph, start)
for _ in range(len(graph.keys())):
for edge in weights.keys():
u, v = edge[0], edge[1]
relax(u, v, weights, distances, predecessors)
for edge in weights.keys():
u, v = edge[0], edge[1]
if distances[v] > distances[u] + weights[edge]:
return False, None, None ## 说明存在权重为负值的环路
return True, distances, predecessors
if __name__ == "__main__":
## 算法导论 图24-4
graph = {
"s": ["t", "y"],
"t": ["x", "y", "z"],
"x": ["t"],
"y": ["x", "z"],
"z": ["s", "x"],
}
weights = {
("s", "t"): 6, ("s", "y"): 7,
("t", "x"): 5, ("t", "y"): 8, ("t", "z"): -4,
("x", "t"): -2,
("y", "x"): -3, ("y", "z"): 9,
("z", "s"): 2, ("z", "x"): 7,
}
flag, distances, predecessors = bellman_ford(graph, weights, "s")
print(flag)
print(distances)
print(predecessors)
## True
## {'s': 0, 't': 2, 'x': 4, 'y': 7, 'z': -2}
## {'s': None, 't': 'x', 'x': 'y', 'y': 's', 'z': 't'}
Dijkistra
Dijkistra算法解决的是带权重的有向图上的单源最短路径问题,该算法要求所有边的权重都为非负值。
给定一个带权重的有向图,该算法在运行过程中维持的关键信息是一组已访问的结点集合,从源结点到该集合中每个结点之间的最短路径已经被被找到。算法重复从结点集中选择最短路径最小的结点,将结点加入到集合,然后对所有从发出的边进行松弛。
在Dijkistra算法的实现中,需要使用最小优先队列来保存结点集,根据每个结点的关键值,快速选择一个“最近”的结点。
因为Dijkistra算法总是选择集合中“最近”的结点来加入到集合中,该算法使用的是贪心策略。虽然贪心策略并不总是能获得最优的结果,但是可以证明,使用贪心策略的Dijkistra算法确实能够计算出最短路径。
Dijkistra算法的运行时间依赖于最小优先队列的实现。如果使用普通的数组来实现最小优先队列,意味着每次都需要遍历所有的未访问的结点才能找到“最近”的结点,算法的总运行时间为。如果使用二叉最小堆来实现最小优先队列,算法的总运行时间为。如果使用斐波那契堆来实现最小优先队列,算法的总运行时间可以改善到。
对于一个用邻接链表表示的带权重的有向图,Dijkistra算法的实现如下所示:
class MinHeap:
pass ## 与Prim算法中的相同
def intialize_single_source(graph, start):
distances = {} ## 结点的关键值
predecessors = {} ## 前驱
for node in graph.keys():
distances[node] = float("inf")
predecessors[node] = None
distances[start] = 0
return distances, predecessors
def relax(u, v, w, distances, predecessors, priority_queue):
if distances[v] > distances[u] + w[(u, v)]:
distances[v] = distances[u] + w[(u, v)]
predecessors[v] = u
priority_queue.decrease_key(v)
def dijkistra(graph, weights, start):
distances, predecessors = intialize_single_source(graph, start)
visited = []
priority_queue = MinHeap(list(graph.keys()), distances)
while len(priority_queue) > 0:
node = priority_queue.extract_min()
visited.append(node)
for adj_node in graph[node]:
relax(node, adj_node, weights, distances, predecessors, priority_queue)
return visited, distances, predecessors
if __name__ == "__main__":
## 算法导论 图24-6
graph = {
"s": ["t", "y"],
"t": ["x", "y"],
"x": ["z"],
"y": ["t", "x", "z"],
"z": ["s", "x"],
}
weights = {
("s", "t"): 10, ("s", "y"): 5,
("t", "x"): 1, ("t", "y"): 2,
("x", "z"): 4,
("y", "t"): 3, ("y", "x"): 9, ("y", "z"): 2,
("z", "s"): 7, ("z", "x"): 6,
}
visited, distances, predecessors = dijkistra(graph, weights, "s")
print(visited)
print(distances)
print(predecessors)
## ['s', 'y', 'z', 't', 'x']
## {'s': 0, 't': 8, 'x': 9, 'y': 5, 'z': 7}
## {'s': None, 't': 'y', 'x': 't', 'y': 's', 'z': 'y'}
Floyd-Warshall
Floyd-Warshall算法容易理解,其运行时间为。与前面的假设一样,负权重的边可以存在,但是不能存在权重为负值的环路。
Floyd算法通常使用邻接矩阵来表示一个图。为了方便起见,对于一个有个结点的带权重的有向图,结点的编号为,可以使用一个大小为的矩阵来表示。也就是说,,其中
图中允许存在负权重的边,但是不包括权重为负值的环路。
对于一个用邻接矩阵表示的带权重的有向图,Floyd-Warshall算法的实现如下所示:
INF = float("INF")
def floyd_warshall(graph):
nodes = list(range(1, len(graph) + 1))
predecessors = []
for i, row in enumerate(graph):
pres = []
for j, ele in enumerate(row):
if i == j:
pres.append(None)
elif ele is INF:
pres.append(None)
else:
pres.append(nodes[i])
predecessors.append(pres)
distances = [row.copy() for row in graph]
n = len(graph)
for k in range(n):
for i in range(n):
for j in range(n):
tmp = distances[i][k] + distances[k][j]
if distances[i][j] > tmp:
distances[i][j] = tmp
predecessors[i][j] = predecessors[k][j]
return distances, predecessors
if __name__ == "__main__":
## 算法导论图25-4
graph = [
[0, 3, 8, INF, -4],
[INF, 0, INF, 1, 7],
[INF, 4, 0, INF, INF],
[2, INF, -5, 0, INF],
[INF, INF, INF, 6, 0],
]
distances, predecessors = floyd_warshall(graph)
print(distances)
print(predecessors)
## [[0, 1, -3, 2, -4], [3, 0, -4, 1, -1], [7, 4, 0, 5, 3], [2, -1, -5, 0, -2], [8, 5, 1, 6, 0]]
## [[None, 3, 4, 5, 1], [4, None, 4, 2, 1], [4, 3, None, 2, 1], [4, 3, 4, None, 1], [4, 3, 4, 5, None]